|
|

|
|
At the moment I'm mostly interested in the applications of computer vision to 3D computer graphics and rendering of Digital Humans. |

|
Dmitrii Pozdeev, Alexey Artemov, Ananta R. Bhattarai, Artem Sevastopolsky ICLR, 2026 project page / paper / video / code / HuggingFace We propose a replacement of standard face landmarks with a dense per-pixel embeddings of a full human head that live in 3D canonical space, consistent across subjects and poses. Predicted embeddings enable a variety of applications, ranging from head tracking to MVS. recorded talks: Cohere Labs (January '26) |
 
|
Rachmadio Noval Lazuardi*, Artem Sevastopolsky*, Egor Zakharov, Matthias Nießner, Vanessa Sklyarova project page / video / arXiv We generate 3D hair strands from a mesh of a human head, drawing the information purely from the sharp features of the mesh surface and not utilizing any color or texture. This allows us to collect a dataset of 400 people with strands. |

|
Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, Matthias Nießner ICCV, 2025 project page / video / arXiv / code Given input speech signal, GaussianSpeech can synthesize photorealistic 3D-consistent talking human head avatars. Realistic and high-quality animations can be generated, including mouth interiors such as teeth, wrinkles, and specularities in the eyes. |
|
Chengan He, Junxuan Li, Tobias Kirschstein, Artem Sevastopolsky, Shunsuke Saito, Qingyang Tan, Javier Romero, Chen Cao, Holly Rushmeier, Giljoo Nam SIGGRAPH (ACM ToG Journal Paper), 2025 project page / arXiv A generative model that transforms separate, disentangled latents for face and hair to a Gaussian rendering of a human head from an arbitrary viewpoint. |

|
Tobias Kirschstein, Javier Romero, Artem Sevastopolsky, Matthias Nießner, Shunsuke Saito ICCV, 2025 project page / video / arXiv Avat3r takes 4 input images of a person's face and generates an animatable 3D head avatar in a single forward pass. The resulting 3D head representation can be animated at interactive rates. |

|
Artem Sevastopolsky, Philip Grassal, Simon Giebenhain, ShahRukh Athar, Luisa Verdoliva, Matthias Nießner 3DV, 2025 project page / video / arXiv / code We learn to generate large displacements for parametric head models, such as long hair, with high level of detail. The displacements can be added to an arbitrary head for animation and semantic editing. |

|
Ananta Raj Bhattarai, Matthias Nießner, Artem Sevastopolsky WACV, 2024 project page / video / arXiv / code EG3D is a powerful {z, camera}->image generative model, but inverting EG3D (finding a corresponding z for a given image) is not always trivial. We propose a fully-convolutional encoder for EG3D based on the observation that predicting both z code and tri-planes is beneficial. TriPlaneNet also works for videos and in real time (check out the Live Demo). |
|
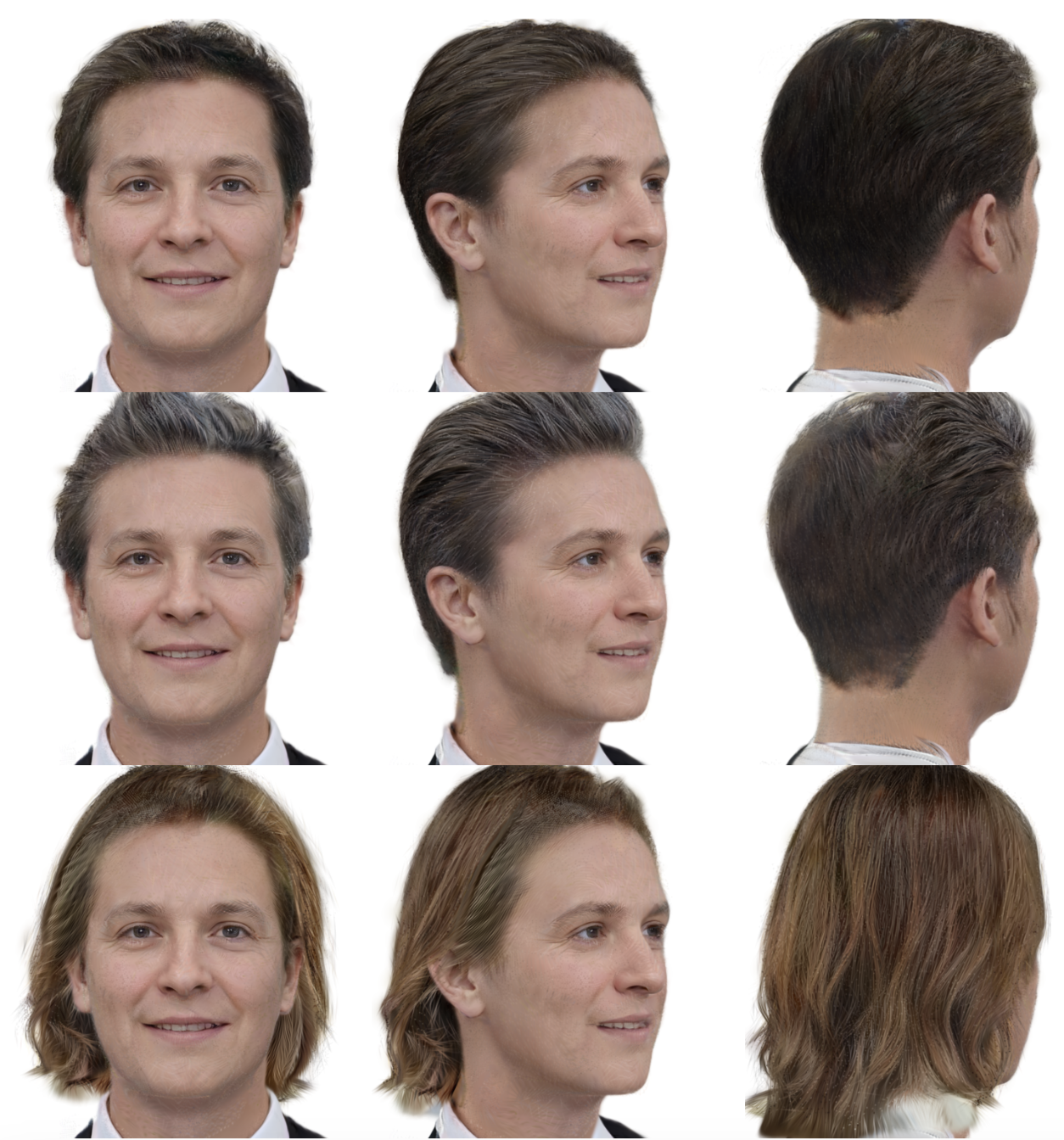
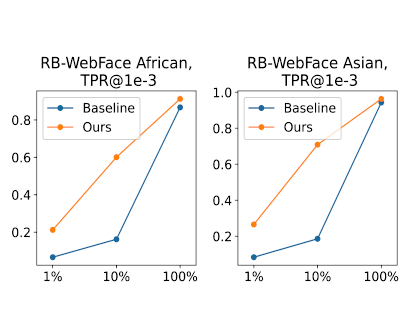
Artem Sevastopolsky, Yury Malkov, Nikita Durasov, Luisa Verdoliva, Matthias Nießner ICCV, 2023 project page / video / arXiv / code & datasets Can the power of generative models provide us with the face recognition on steroids? Random collections of faces + StyleGAN are the secret sauce. We release the collections themselves, as well as a new fairness-concerned testing benchmark. |

|
Artem Sevastopolsky, Savva Ignatiev, Gonzalo Ferrer, Evgeny Burnaev, Victor Lempitsky project page / video / arXiv / talk video By taking a simple selfie-like capture by a smartphone, one can easily create a relightable 3D head portrait. The system is based on Neural Point-Based Graphics. media coverage: IEEE Spectrum (March '21) |
|
|
Maria Kolos*, Artem Sevastopolsky*, Victor Lempitsky 3DV, 2020 project page / video / arXiv / code An extension of Neural Point-Based Graphics that can render transparent objects, both synthetic and captured in-the-wild. |
 
|
Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, Victor Lempitsky ECCV, 2020 project page / video / arXiv / code Given RGB(D) images and a point cloud reconstruction of a scene, our neural network generates extreme novel views of the scene which look highly photoreal. |
 
|
Artur Grigorev, Artem Sevastopolsky, Alexander Vakhitov, Victor Lempitsky CVPR, 2019 project page / arXiv / supmat How would I look in a different pose? Or in different clothes? A ConvNet with coordinate-based texture inpainting to the rescue. |
|
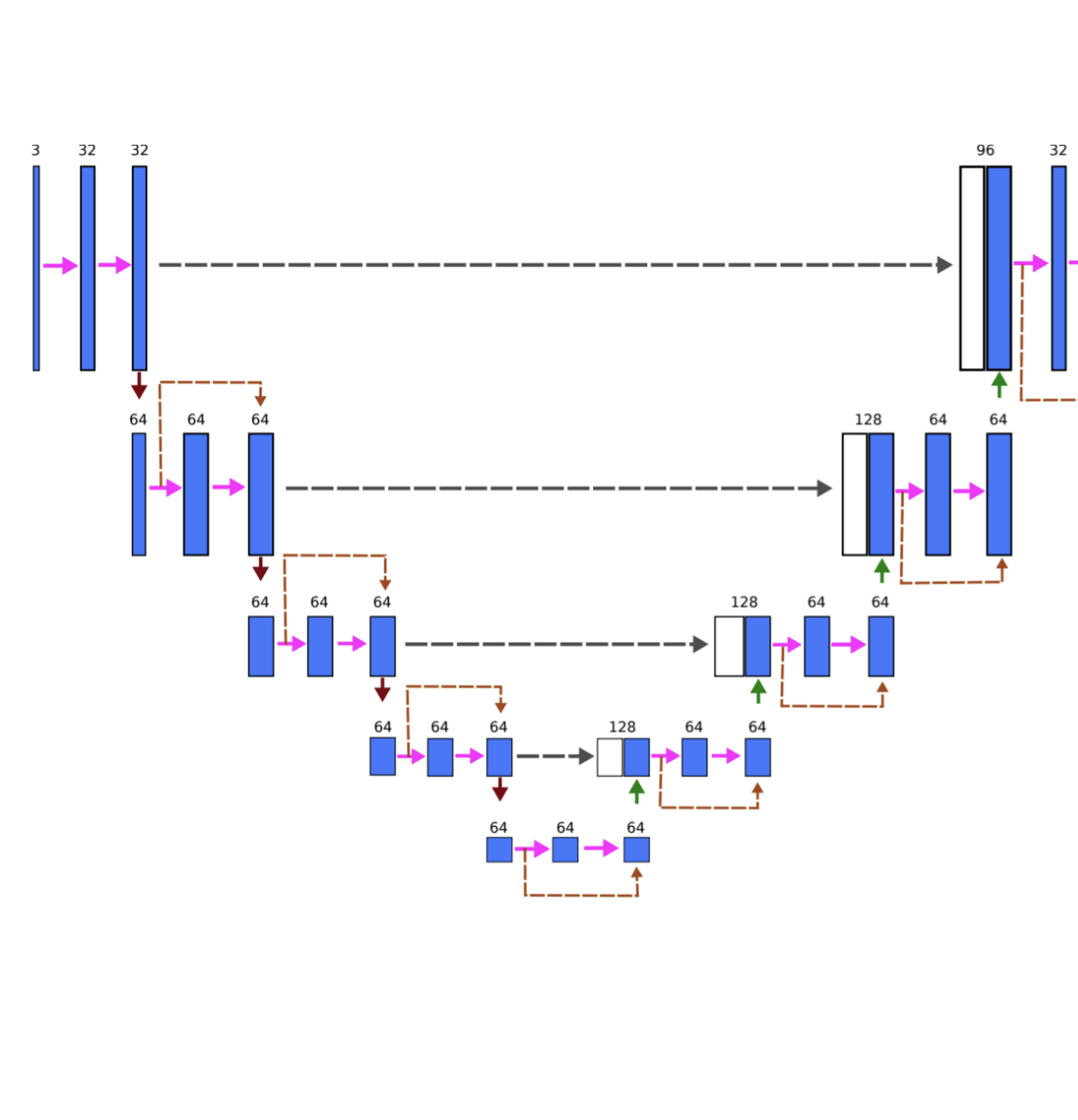
Artem Sevastopolsky, Stepan Drapak, Konstantin Kiselev, Blake M. Snyder, Jeremy D. Keenan, Anastasia Georgievskaya SPIE Medical Imaging, 2019 arXiv An advanced version of "Optic disc and cup segmentation methods..." (see below), where a segmentation is performed by a U-Net stacked multiple times, and a validation is performed on large amounts of data provided by UCSF. |
 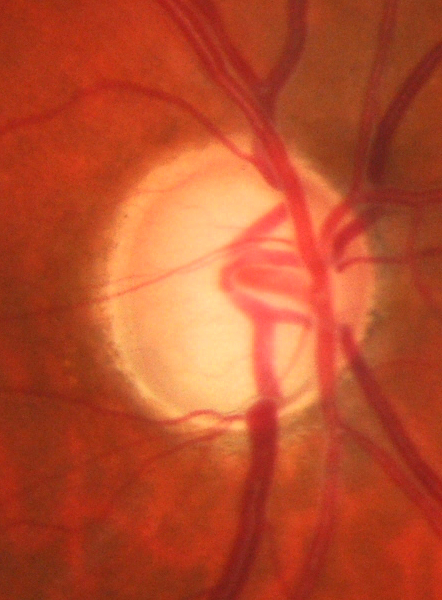
|
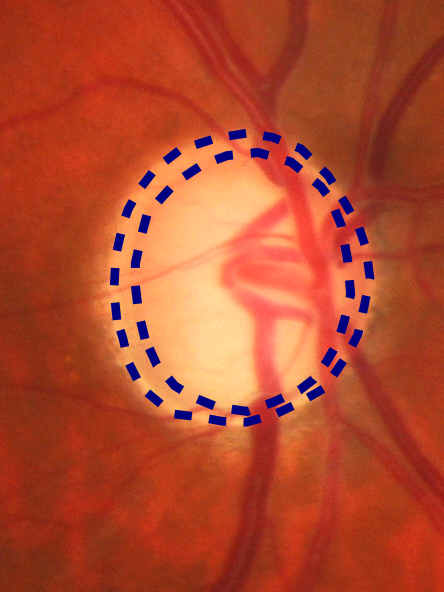
Artem Sevastopolsky, Pattern Recognition & Image Analysis, 2017 arXiv / code Automatic segmentation of two organs on an eye fundus image allows medical doctors to make more accurate early diagnosis of glaucoma and evaluate its progression over time. |
|
The webpage template was borrowed from the exciting page of Jon Barron. |